%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Speech recognition
Moonshine Web
Moonshine Web is a simple application built with React and Vite, running on Moonshine Base, a powerful speech recognition model optimized for fast and accurate automatic speech recognition (ASR), particularly suited for resource-constrained devices. The application runs locally in the browser, utilizing Transformers.js and WebGPU for acceleration (with WASM as an alternative). Its significance lies in providing users with a serverless solution for local speech recognition, which is especially crucial for scenarios requiring swift processing of voice data.
Speech Recognition
59.3K
Aixploria
Aixploria is a website focused on artificial intelligence, offering an online directory of AI tools that helps users find and select the best AI solutions to meet their needs. With a simplified design and intuitive search engine, users can easily search for various AI applications using keywords. Aixploria not only provides a list of tools but also publishes articles explaining how each AI works, helping users understand the latest trends and popular applications. Additionally, Aixploria features a 'Top 10 AI' section that is updated in real-time, allowing users to quickly learn about the top AI tools in each category. Aixploria is suitable for anyone interested in AI, whether beginners or experts, and valuable information can be found here.
AI information platform
632.0K
Sensevoicesmall
SenseVoiceSmall is a speech foundation model that supports multiple speech understanding capabilities, including automatic speech recognition (ASR), spoken language recognition (LID), speech emotion recognition (SER), and audio event detection (AED). After training for more than 400,000 hours on data, the model supports more than 50 languages and has a recognition performance that surpasses the Whisper model. The SenseVoiceSmall model, which is a small model, uses a non-autoregressive end-to-end framework with extremely low inference latency and handles a 10-second audio in only 70 milliseconds, which is 15 times faster than Whisper-Large. In addition, SenseVoice also provides convenient fine-tuning scripts and strategies, supports multi-concurrency request service deployment pipelines, and the client languages include Python, C++, HTML, Java, and C#.
AI speech recognition
83.4K
Fresh Picks

Streamspeech
StreamSpeech is a real-time speech-to-speech translation model based on multi-task learning. By learning translation and synchronization strategies in a unified framework, it effectively identifies the translation timing within streaming voice input, achieving a high-quality real-time communication experience. The model has demonstrated leading performance on the CVSS benchmark and can provide low-latency intermediate results, such as ASR or translation.
AI Translation
88.0K
Any GPT
AnyGPT is a unified large-scale language model that employs discrete representations for the uniform processing of various modalities, including voice, text, images, and music. AnyGPT can be trained stably without modifying the architecture or training paradigm of existing large-scale language models. It relies entirely on data-level preprocessing, which facilitates the seamless integration of new modalities into the language model, akin to the addition of a new language. We have constructed a text-centric multi-modal dataset for multi-modal alignment pre-training. Utilizing generative models, we have created the first large-scale multi-modal instruction dataset from any modality to any modality. It consists of 108,000 multi-turn dialogue examples with different modalities intertwined, enabling the model to handle combinations of any modal input and output. Experimental results indicate that AnyGPT can facilitate multi-modal dialogues from any modality to any modality and achieve performance comparable to dedicated models across all modalities, demonstrating that discrete representations can be effectively and conveniently used for unifying multiple modalities in language models.
AI Model
98.0K
English Picks
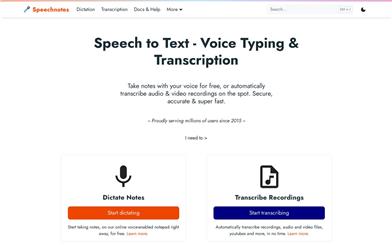
Speechnotes
Speechnotes is a reliable and secure web-based speech-to-text tool that can quickly and accurately transcribe audio and video recordings, as well as allow for dictation notes instead of typing, saving you time and effort. Speechnotes features voice commands for punctuation and formatting, automatic capitalization, and easy import and export options, providing you with an efficient and user-friendly dictation and transcription experience. Speechnotes has been serving millions of users since 2015.
Speech-to-text
118.7K

Transcribe
Transcribe ~ Speech to Text is an iOS speech-to-text application. It leverages OpenAI's Whisper technology and Apple's Neural Engine to achieve high-precision speech recognition, directly transcribing audio and video files into readable text. It supports both offline and cloud-based recognition modes. Applicable to various speech-to-text needs, it is simple and easy to use.
AI speech-to-text
77.3K
Hanami Live Translator
Hanami Live Translator is a real-time translation tool that captures any audio from WINDOWS speakers and microphones. It utilizes lightweight multi-process and chunk processing of audio, with each chunk taking approximately 3-5 seconds to process. The application creates a hardware loopback via low-level access, allowing it to listen to content even when the speakers are muted. It uses the soundcard library to capture audio signals, the SpeechRecognition library to convert binary audio to text, and the selenium library to simulate network calls to deepl servers for free translation. The application requires an internet connection to operate and logs all actions through the Traces.log file.
AI Translation
124.8K
Speechevalpro API
The voice evaluation API is based on independently developed education AI voice models, integrating core technologies such as voice evaluation and speech recognition. It provides high-quality, multi-dimensional Chinese and English pronunciation evaluation APIs to help customers create intelligent learning products and realize human-machine interaction. Product features include core patented technology, stable and reliable AI models, and rich evaluation dimensions, including completeness, accuracy, and fluency. Pricing strategies include free trials, professional versions, and enterprise versions. Supports various evaluation scenarios, such as homework and exams. Supports HTTP and WebSocket protocols.
Education
70.7K
Easy Save AI
Translate.video is an AI-powered video translation tool that can help users automatically translate the audio and subtitles of videos into multiple languages. Utilizing advanced speech recognition and machine translation technologies, the tool ensures efficient and accurate video content translation. Users simply need to upload a video or input a video link, select the target language, and they can quickly obtain the translated video. Translate.video also supports automatic subtitle generation and editing, making it convenient for users to make fine adjustments and proofread the subtitles. The tool offers flexible pricing plans, including various packages and payment options, to cater to diverse user needs.
Translation
73.7K
Ttslabs
TTSLabs is an online voice synthesis and speech recognition service, offering high-quality, natural and fluent voice synthesis and accurate and reliable speech recognition. Through simple API calls, users can convert text to real speech and convert speech to text. TTSLabs supports multiple voice styles and multiple languages, featuring fast response and high efficiency. Pricing is flexible and transparent, suitable for both individual developers and enterprise users.
Speech-to-text
59.3K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.8K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.2K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M